HPC & AI Communication
Since joining AWS Annapurna Labs in 2019, my work has focused on the software stack that makes large-scale distributed computing possible — from bare-metal RDMA networking all the way up to collective communication libraries used by today's largest AI training and inference clusters. The common thread is latency and bandwidth: squeezing every nanosecond out of the interconnect so that thousands of GPUs or CPUs can communicate as efficiently as possible.
RDMA Networking & AWS EFA
AWS Elastic Fabric Adapter (EFA) is a custom RDMA-capable network interface card built by Annapurna Labs for EC2 instances. Unlike traditional TCP/IP networking, EFA bypasses the OS kernel and allows applications to push and pull data directly to and from remote memory — dramatically reducing latency and CPU overhead for tightly-coupled workloads.
My work involves developing and maintaining the EFA software stack: the kernel driver, the rdma-core user-space verbs layer, and the higher-level libraries built on top. A key focus is ensuring that performance scales correctly as instance sizes grow — from a single socket to hundreds of nodes connected across multiple racks.
libfabric (Open Fabric Interfaces)
libfabric is the open-source network fabric API maintained by the OFI working group. It provides a portable, high-performance interface over heterogeneous RDMA transports — EFA, InfiniBand, RoCE, shared memory — so that applications and MPI runtimes can target any network without code changes.
I am one of the primary maintainers of the EFA provider within libfabric, responsible for the driver-level interface between libfabric and the EFA hardware. Key contributions include:
- Peer API — co-designed and implemented the libfabric Peer API, an interface that allows providers to short-circuit intra-node communication by delegating directly to a shared-memory provider, eliminating redundant memory copies. This shipped in libfabric 1.19.0 and reduced intra-node MPI latency by ~50% and collective latency by up to 50% on ARM64 (see AWS HPC Blog).
- High-PPS RMA — added WQE-level packets-per-second hints and a dedicated
RMA bandwidth test (
fi_efa_rma_bw) to expose and exercise high-throughput one-sided communication paths on EFA. - CI infrastructure — maintained the automated testing pipeline (libfabric-ci-scripts) to ensure correctness across EFA hardware generations and software configurations.
Open MPI
Open MPI is the standard open-source MPI implementation for HPC. I contribute primarily to the EFA transport layer and collective communication performance on AWS instances.
A significant area of work has been intra-node performance. Prior to the Peer API work, Open MPI on EFA instances routed intra-node messages through multiple provider layers, adding 0.4–0.5 µs of unnecessary latency on small messages. Implementing Peer API support in Open MPI's OFI layer — in conjunction with the libfabric changes — eliminated this overhead and delivered ~10% wall-clock improvement in real HPC applications such as OpenFOAM CFD simulations.
AI & ML Communication at Scale
As large-scale deep learning has become a dominant HPC workload, the communication library stack has had to evolve alongside it. Rather than MPI collectives, distributed training frameworks like PyTorch use NCCL for GPU-to-GPU collective communication (AllReduce, AllGather, etc.).
aws-ofi-nccl is a plugin that routes NCCL traffic over libfabric and EFA, giving distributed training jobs access to EFA's low-latency RDMA fabric without any changes to user code. I have contributed to the EFA transport path and performance tuning within this plugin.
More recently, the rise of LLM inference has created new communication patterns — particularly disaggregated inference, where prefill and decode phases run on separate nodes and require fast KV-cache transfers between them. I have been collaborating on NIXL (NVIDIA Inference Xfer Library), which provides a pluggable abstraction for these transfers across CPU/GPU memory and storage, and UCCL, a next-generation GPU communication library targeting both collective and P2P workloads with greater flexibility than NCCL.
Past Research: Nuclear Physics
Before joining AWS, I obtained a PhD in physics from the University of Washington under Prof. Aurel Bulgac. My research applied density functional theory (DFT) and its time-dependent extension (TDDFT) to superfluid many-fermion systems — nuclear structure, fission dynamics, and quantum many-body phenomena.
Nuclear Energy Density Functional (NEDF)
We constructed SeaLL1, a new NEDF with only 7 uncorrelated parameters, achieving an r.m.s. binding energy of 1.74 MeV across 606 even-even nuclei and charge radii of 0.034 fm across 235 nuclei — while producing reasonable fission barriers for 240Pu.
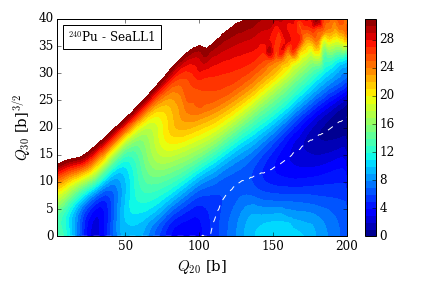
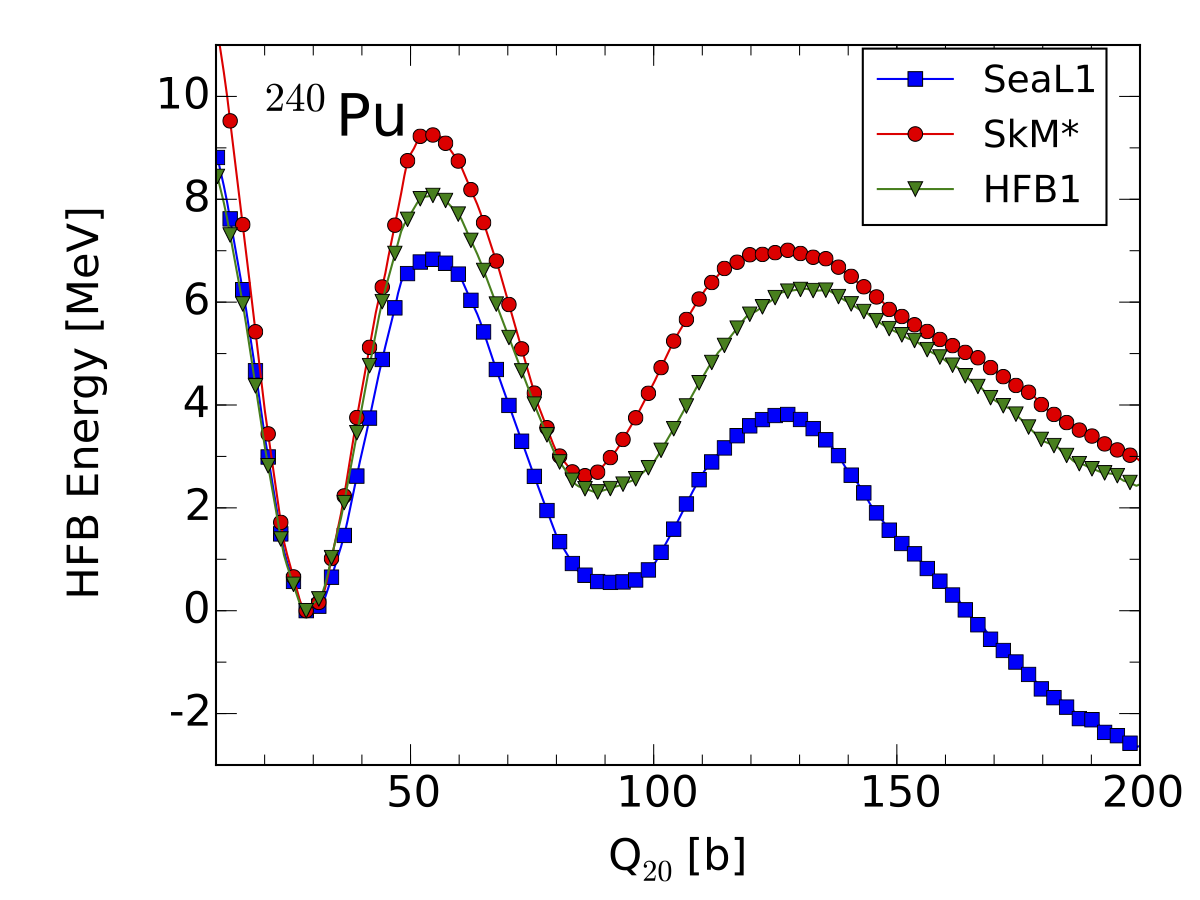
Nuclear Fission Dynamics
Using TDDFT, we performed fully microscopic simulations of induced fission in 240Pu — tracking the system from initial excitation through saddle point, scission, and fragment de-excitation. This work provided new insight into fission fragment spin correlations and the role of quantum fluctuations and dissipation in the fission process.